-
2022년 11월 23일 수요일(R간단한 문제풀이 및 그래프그리기)개발/개발일지(국비지원) 2022. 11. 23. 16:34728x90
● 문제
x=c(2,-1,3,7,0.5,8) #벡터데이터
1.x=c(2, -1, 3, 7, 0.5, 8)가 실행되었다 하자. 다음 물음을 R 언어로 답하시오.
①6, 2, 4번째 원소를 동시에 찾아라.
x[c(6,2,4)] ▶[인덱스] R에서는 인덱스 1부터 시작.
▶결과) [1] 8 -1 7
②x의 원소 중 0보다 큰 값을 찾아라.
x[x>0] ▶ 요소의 조건을 인덱스로 사용
▶결과) [1] 2.0 3.0 7.0 0.5 8.0
③짝수 원소들을 찾아라.
x[x%%2==0]
▶결과) [1] 2 8
④x에서 홀수원소를 찾아 제거하라.
x[x%%2==1]=NA ▶ NA=결측값
x▶결과) [1] 2.0 NA NA NA 0.5 8.0
2.다음과 같은 번호(ID), 성명(name), 성적(score)를 성분으로 하는 리스트가 있다.
물음에 답하라.
L=list(ID=c(1,2,3),
name=c('Kim', 'Lee', 'Park'),score=c(80, 95, 75))
L
① length(L)은 얼마이며, 이것은 무엇을 의미하는가?
length(L) ▶ 열의 갯수. 데이터의 종류의 갯수
▶결과) [1] 3
② 점수가 75점인 사람을 80으로 수정하라
L$name[L$score==75] ▶75점인 사람의 이름 ▶결과) [1] "Park"
L$score[L$score==75]=80 ▶ 75점을 80점으로 변경▶결과) [1] 80 95 80
③ L$name=='Park'의 결과를 쓰고, 무엇을 의미하는지 설명하라.
L$name=='Park' ▶ name이 Park여부 boolean 으로 출력
▶ 결과는 false , false , true
▶ Kim=false , Lee=false Park==true
④ L$score[L$name=='Park']의 결과를 쓰고, 문장이 무엇을 의미하는지 설명하라.
L$score[L$name=='Park'] ▶이름이 Park인사람의 성적만 조회 #name이 Park여부 boolean 으로 출력
▶결과는 false , false , true
▶ Kim=false , Lee=false Park==true
⑤ 1번 학생의 이름과 성적을 알아내는 문장을 만들어 보아라.
cat(L$name[L$ID==1],L$score[L$ID==1]) ▶cat : 화면에 여러개의 변수 출력
union(L$name[L$ID==1], L$score[L$ID==1]) ▶union : 두개의 데이터를 합한 객체
C(L$name[L$ID==1],L$score[L$ID==1])▶결과) Kim 80
matrix를 이용하여 햄버거 영양 데이터 분석
기본적으로 매트릭스는 열 우선으로 생성되는데,
▶byrow=T : 행우선으로 데이터를 설정해주는 속성.
burger <- matrix(c(514,917,11,533,853,13,566,888,10),nrow=3,byrow = T)
burger▶결과)
[,1] [,2] [,3]
[1,] 514 917 11
[2,] 533 853 13
[3,] 566 888 10
행과 열의 이름을 지정해주기
rownames(burger)=c('M','L','B') # =,<- 다 사용가능
burger
colnames(burger)<-c('kcal','na','fat')▶결과)
kcal na fat
M 514 917 11
L 533 853 13
B 566 888 10
#M사의 나트륨 함량조회 #matrix[행,열]
burger['M','na']▶결과) 917
#M사의 데이터조회 #matrix[행,] ,를 안써주면 뒤에 열이있다는걸 몰라서 필수
burger['M',]▶결과)
kcal na fat
514 917 11
#모든 회사의 kcal 데이터 조회
burger[,'kcal']▶결과)
M L B
514 533 566
###dataframe을 이용한 햄버거 영양 성분 분석
kcal <- c(514,533,566)
na <- c(917,853,888)
fat <- c(11,13,10)
menu <-c('새우','불고기','치킨')
burger <-data.frame(kcal,na,fat,menu)▶결과)
kcal na fat menu
1 514 917 11 새우
2 533 853 13 불고기
3 566 888 10 치킨
#행의이름 설정
rownames(burger) <-c('M','L','B')
burger
▶결과)kcal na fat menu
M 514 917 11 새우
L 533 853 13 불고기
B 566 888 10 치킨
# 'M','B' 회사의 menu값 조회
burger[c('M','B'),'menu']
▶결과)[1] "새우" "치킨"
# 'M','B' 회사의 menu,kcal값 조회
burger[c('M','B'),c('menu','kcal')]
▶결과)menu kcal
M 새우 514
B 치킨 566
R에서 제공해주는 iris 데이터 이용하기
head(iris) :처음 6개의 데이터만 출력
tail(iris) :마지막 6개의 데이터만 출력
#행,열의 갯수 조회하기
dim(iris) #행,열의 갯수 ->결과:150행, 5열
nrow(iris) #행의 갯수 ->결과:150행
ncol(iris) #열의 갯수 ->결과:5열
colnames(iris) ->결과: 열의 이름 출력
str(iris) -> 결과:dataframe 데이터의 요약 정보
iris 데이터의 품종만 조회
iris[,'Species'] ->컬럼명으로 조회
iris[,5] ->컬럼의 순서(인덱스)로 조회
levels(iris[,5])
품종별 데이터 건수 출력하기
table(iris[,5]) ->결과: setosa:50 / versicolor:50 / virginica:50
#5번째 컬럼을 제외하고 조회
iris[,-5]▶결과: 5번째컬럼인 species를 제외한 4개의컬럼출력
Sepal.Length Sepal.Width Petal.Length Petal.Width
876.5 458.6 563.7 179.9
#5번컬럼을 제외하고, 열별 합계 조회
colSums(iris[,-5])
#5번컬럼을 제외하고 열별 평균 조회하기
colMeans(iris[,-5])
#5번컬럼을 제외하고 행별 합계 조회하기
rowSums(iris[,-5])
#5번컬럼을 제외하고 행별 평균 조회하기
rowMeans(iris[,-5])
#품종이setosa인 데이터만 iris1에 저장
iris1 <- subset(iris,Species=='setosa')
iris1
str(iris1)▶결과) setosa인 데이터에 해당하는 값만출력
#Sepal.Length >5 이고 , Sepal.Width>4인 행만 iris에 저장하기
iris2 <-subset(iris,Sepal.Length>5 & Sepal.Width>4)
iris2
#열 조회하기
# Sepa.Lenght >5 크고, Sepal.Width >4보다 큰 행의
# Petal.Length , Petal.Width , Species 컬럼만 조회하기
iris2[,c(3,4,5)] ▶ 컬럼의 인덱스값으로 선택
iris2[,c('Petal.Length','Petal.Width','Species')] ▶ 컬럼의 이름으로 선택
iris2[,c(3:5)] #c(3:5) ▶ 3번인덱스~5번인덱스 선택
subset(iris,Sepal.Length >5 & Sepal.Width >4)[,c(3,4,5)]▶ iris에서 3~5컬럼중 길이는 5이상 넓이는 4이상인 값 출력
sum(iris[,1]) #1열의 합의 값
mean(iris[,1]) #1열의 평균값
max(iris[,1]) #1열의 최대값
min(iris[,1]) #1열의 최소값
#iris 데이터의 자료형
class(iris) ▶ 해당 자료형을 출력해준다
is.data.frame(iris) ▶ 해당데이터가 data.frame이면 true출력 아니면 false
is.matrix(iris) ▶ 해당데이터가 matrix면 true출력 아니면 false
미국의 주 정보 ; state.x77
state.x77
class(state.x77) ▶ matrix , array
state <- data.frame(state.x77) ▶ 데이터의 자료형을 기존 matrix에서 data.frame으로 변경해준다
class(state) ▶ 자료형이 변경된것을 확인할 수 있다.
trees 데이터를 이용한 데이터 추출
trees
직경의 평균값 구하기
mean(trees[,1]) ▶ 1번컬럼에 해당하는 평균값
mean(trees[,'Girth']) ▶ Girth에 해당하는 평균값
mean(trees$Girth) ▶ Girth에 해당하는 평균값
str(trees) -> 해당데이터의 정보를 볼수있다.
① 직경(Girth)은 화원에서 보유한 벚나무의 평균보다 커야 한다
tree1 <- subset(trees,Girth > mean(trees[,'Girth']))
tree1
nrow(tree1)
① 직경(Girth)은 화원에서 보유한 벚나무의 평균보다 커야한다
② 높이(Height)는 80보다 커야한다.
③ 부피(Volume)는 50보다 커야한다
#3가지를 모두 만족하는 나무의 갯수 출력하기
tree2 <- subset(trees,Girth >mean(trees[,'Girth']) & Height > 80 & Volume>50)
tree2
nrow(tree2)
● 종업원의 팁 자료형 분석하기 : reshape2 패키지에 저장된 데이터타입
tips
reshape2 패키지 설정하기(의존성 주입)
install.packages('reshape2')
library(reshape2) ▶ 설정된 패키지 사용하기.
tips
.libPaths() ▶ 패키지가 설정된 폴더를 조회하기 폴더에 한글경로 안됨.
▶ .libPaths(한글이름없는 폴더로 다시 지정) ▶ 패키지경로 설정
class(tips)
str(tips)
total_bill : 전체 결제금액
tip : 팁금액
sex : 성별
smoker : 흡연여부
day : 요일.
time : 점심/저녁
size : 인원수
head(tips)
#요일별 팁을 받은 갯수를 조회하기
tips$day ▶ tips데이터에서 day컬럼만 조회한다.table(tips$day) ▶ tips데이터에서 day컬럼만 테이블화해서 보여준다
table(tips[,5]) ▶ tips에서 5번째 컬럼만 테이블화해서 출력한다.
table(tips[,'day']) ▶ tips에서 'day'인 컬럼만 테이블화해서 출력한다.
#시간별 팁을 받은 갯수를 조회하기
table(tips[,'time']) ▶ tips데이터에서 'time'인 컬럼만 테이블화해서 보여준다
table(tips$time) ▶ tips데이터에서 'time'인 컬럼만 테이블화해서 보여준다
table(tips[,6]) ▶ tips에서 6번째 컬럼만 테이블화해서 출력한다.
#시간대별로 Dinner 인경우만 조회하여 dinner 데이터에 저장하고,
# Lunch 인 경우만 lunch 데이터에 저장하기
dinner <- subset(tips,time=='Dinner')▶ 새로운 dinner데이터에 subset으로 time이 Dinner인 값만 저장해준다
kimlunch <- subset(tips,time=='Lunch')▶ 새로운 kimlunch데이터에 subset으로 time이 Dinner인 값만 저장해준다
dinner ▶
kimlunch
# dinner와 lunch 데이터 셋에서 결제금액,팁,인원수의 평균구하기● dinner
방법1)
mean(dinner[,'total_bill']) ▶ dinner 데이터의 총결제금액의 평균값이 출력된다.
mean(dinner[,'tip']) ▶ dinner 데이터의 팁의 평균값이 출력된다.
mean(dinner[,'size']) ▶ dinner 데이터의 인원수의 평균값이 출력된다.방법2)
colMeans(dinner[1])
colMeans(dinner[2])
colMeans(dinner[7])● kimlunch
방법1)
mean(kimlunch[,'total_bill']) ▶ kimlunch 데이터의 총결제금액의 평균값이 출력된다.
mean(kimlunch[,'tip']) ▶ kimlunch 데이터의 팁의 평균값이 출력된다.
mean(kimlunch[,'size']) ▶ kimlunch 데이터의 인원수의 평균값이 출력된다.방법2)
colMeans(kimlunch[1])
colMeans(kimlunch[2])
colMeans(kimlunch[7])#결제금액 대비 팁의 비율조회하기\
tips$tip/tips$total_bill
#결제금액 대비 팁의 비율이 높은 값 조회하기
max(tips$tip/tips$total_bill)
#결제금액 대비 팁의 비율이 낮은 값 조회하기
min(tips$tip/tips$total_bill)
#dinner , kimlunch 데이터의 팁의 비율의 평균 조회하기
#dinner
dinner$tip/dinner$total_bill
mean(dinner$tip/dinner$total_bill)
#kimlunch
kimlunch$tip/kimlunch$total_bill
mean(kimlunch$tip/kimlunch$total_bill)● 그래프
시각화
y2017 <- c(116215, 3437, 26183, 7522, 147, 1411)
y2016 <- c(104359, 3393, 24527, 7058, 102, 975)
#rbind : 행을 연결
df<-rbind(y2017,y2016)
▶결과)[,1] [,2] [,3] [,4] [,5] [,6]
y2017 116215 3437 26183 7522 147 1411
y2016 104359 3393 24527 7058 102 975
컬럼이름 설정
colnames(df) <- c('시','소설','수필','평론','희곡','기타')▶결과)
시 소설 수필 평론 희곡 기타
y2017 116215 3437 26183 7522 147 1411
y2016 104359 3393 24527 7058 102 975
막대 그래프
barplot(df, main = '문인잡지의 작품 발표 현황',
xlab = '작품 종류',ylab = '발표 건수',
col = c('maroon','indianred'),
legend.text = c('2017','2016'))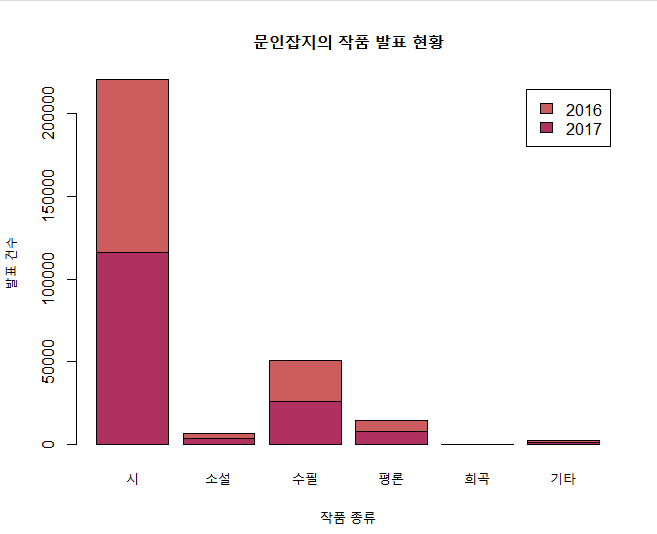
막대그래프 결과
히스토그램 : 자료의 분포를 시각화
cars #제동거리
dist <- cars[,2]
dist
hist(dist)
cars 결과
#breaks=12 : 값의 구간을 12개 분리
hist(dist,breaks=12)
구간분리를 했을때 cars
#h$breaks : 값의 구간값
#h$counts : 값의 구간별 빈도수(갯수). 막대의 크기
#h$density : 밀도값.
#h$mids : 중간값 (0-20의 중간값, 20-40의 중간깂,,, 100-120의 중간값)
#h$xname : 데이터의 이름
#h$equidist : 그래프간격이 일정?
install.packages('Stat2Data') ▶ 데이터를 사용하기위해 설치
library(Stat2Data) ▶ 설치한 데이터 사용하기위해 설정
data('Diamonds')
str(Diamonds)
head(Diamonds)
색상 설정
color <- rep('orange', 9)
#캐럿당 가격의 분포를 히스토그램으로 출력하기
h<-hist(Diamonds$PricePerCt,main="캐럿당 가격의 분포",
xlab='캐럿당 가격', ylab='빈도수',col='skyblue')
Diamonds-색상설정을 반영한 값
#캐럿당가격의 분포를 히스토그램으로 출력하기
color[which.max(h$counts)] <- 'red'
color[3] <-'yellow'
#which.max(h$counts) : h$counts 데이터 중 가장큰값의 인덱스를 리턴
# 빈도수가 많은 막대 색상을 red로 변경
h<-hist(Diamonds$PricePerCt,main="캐럿당 가격의 분포",
xlab='캐럿당 가격', ylab='빈도수',col=color)
원하는 그래프 지정색으로 변경
#### 상자그래프
# 사분위수를 시각화
# 1사분위수 : 25%해당하는 값
# 중간값 : 50%해당하는 값
# 3사분위수 : 75%해당하는 값
# 최대값 : 100%해당하는 값
# 특이값 : 범위 밖에 존재하는 값
cars
str(cars)
dist <- cars[,2]
boxplot(dist,main='자동차 제동거리')
boxplot.stats(dist) #박스그래프의 설명
박스그래프
# $stats : 2 26 36 56 93
# 2: 최소값 ->맨밑 실선
# 26 : 1사분위값 -> 박스 밑선
# 36 : 중간값 50%값 ->굵은실선
# 56 : 3사분위값 -> 박스위에선
# 93 : 최대값 . 80-100 실선
# $n : 관측값의 갯수
# $conf : 중간값의 신뢰구간
# $out : 특이값
#그룹화된 박스그래프
boxplot(Petal.Length~Species,
data=iris,
main="품종별별 꽃잎의 길이",
col=c('green','yellow','blue'))
그룹화 박스그래프
###산점도
# 두 변수사이의 관계 파악에 사용되는 그래프
# 상관계수와 밀접함.
# A,B 변수가 있는 경우
# 상관계수 : A 1이 변동되는 경우 B 1 이 변동됨. 1
# 상관계수 : A 2이 변동되는 경우 B 1 이 변동됨. 0.5
산점도 그래프
mtcars :자동차연비 데이터
mpg : 연비데이터
wt : 차량의무게
plot(mtcars$wt,mtcars$mpg, main="중량별 연비",
xlab="중량",ylab="연비",col="blue")
#상관계수 ▶ 중량이높을수록 연비가 낮다는 결론
cor(mtcars$wt, mtcars$mpg)파이썬을 들어가기전에 R을 간단하게 배웠다.
파이썬과 비슷한부분이 있어, 일단 선행으로 학습하고,
내일부터 파이썬을 시작하기로했다.
기초적인부분이라 이해하는데 어려운부분은 없었던것같다.
728x90'개발 > 개발일지(국비지원)' 카테고리의 다른 글
2022년 11월 25일 금요일 파이썬(조건문,반복문예제) (0) 2022.11.24 2022년 11월 24일 파이썬 설치 및 기초학습(범위지정출력,산술연산자,형변환함수) (0) 2022.11.24 2022년 11월 22일 R설치 및 기본개념 (0) 2022.11.22 2022년 11월 15일 화요일(컨트롤러,service,dao,mapper부분 넣기) (0) 2022.11.15 2022년 11월 14일 월요일 (0) 2022.11.14